Fish Audio Open-Sources S2: Fine-Grained Control Meets Production Streaming
Mar 9, 2026
S2 open source is available via the project's GitHub repository and HuggingFace.
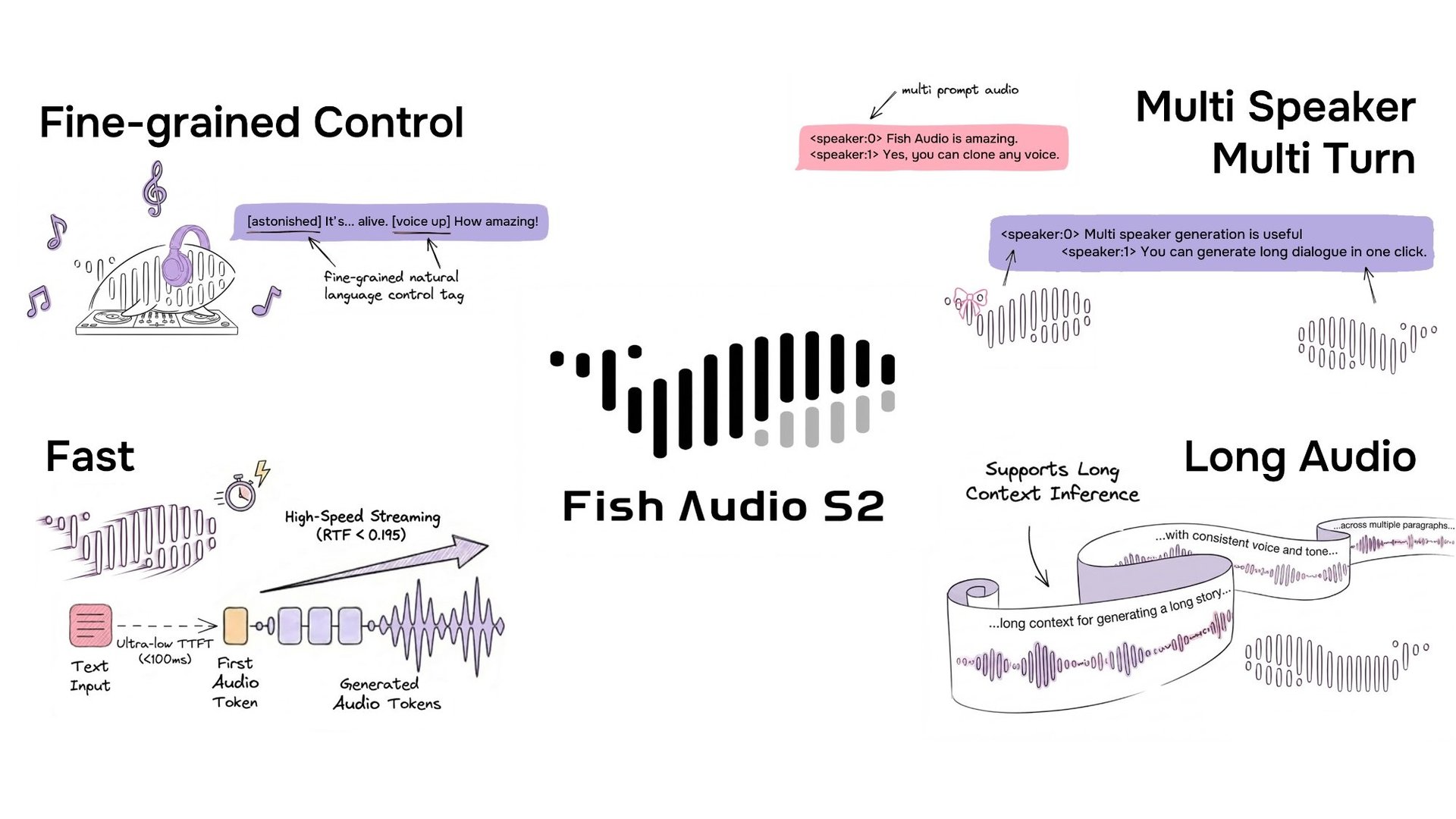
Fish Audio has open-sourced S2, a text-to-speech model that supports fine-grained inline control of prosody and emotion using natural-language tags like [laugh], [whispers], and [super happy]. Trained on over 10 million hours of audio across approximately 50 languages, the system combines reinforcement learning alignment with a dual-autoregressive architecture. The release includes model weights, fine-tuning code, and an SGLang-based streaming inference engine.
Fine-Grained Inline Control via Natural Language
S2 enables Inline control over speech generation by embedding natural-language instructions directly at specific word or phrase positions within the text. Rather than relying on a fixed set of predefined tags, S2 accepts free-form textual descriptions — such as [whisper in small voice], [professional broadcast tone], or [pitch up] — allowing open-ended expression control at the word level.
On the Audio Turing Test, S2 achieves a posterior mean of 0.515 with instruction rewriting, compared to 0.417 for Seed-TTS and 0.387 for MiniMax-Speech. On EmergentTTS-Eval, it reaches an overall win rate of 81.88% against a gpt-4o-mini-tts baseline — the highest among all evaluated models, including closed-source systems from Google and OpenAI.
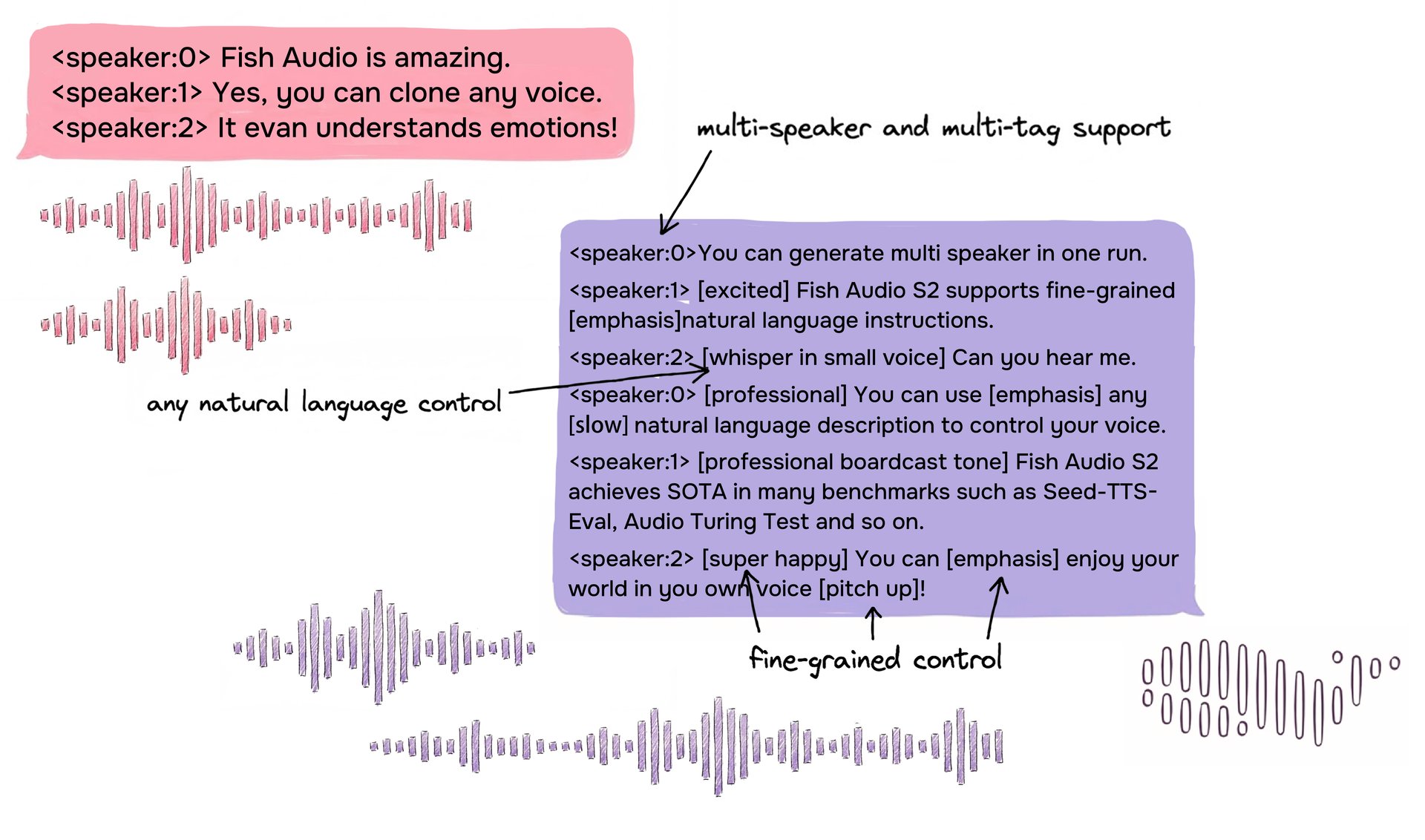 Example of S2 input format showing multi-speaker dialogue with free-form natural-language inline tags for fine-grained control.
Example of S2 input format showing multi-speaker dialogue with free-form natural-language inline tags for fine-grained control.
A Unified Recipe: Data Curation and RL Rewards from the Same Models
A core architectural decision in S2 is that the same models used to filter and annotate training data are directly reused as reward models during reinforcement learning:
- Speech quality model scores audio across dimensions like SNR, speaker consistency, and intelligibility during data filtering — then serves as the acoustic preference reward during RL.
- Rich-transcription ASR model (continue pretrained from Qwen3-Omni-30B-A3B) generates caption-augmented transcripts with inline paralinguistic annotations during data curation — then provides the intelligibility and instruction-following reward by re-transcribing generated audio and comparing it against the original prompt.
This dual-purpose design eliminates the distribution mismatch between pre-training data and post-training objectives by construction — a problem that remains unaddressed in other TTS systems that train reward models separately from their data pipelines.
Inside the Model: Dual-AR Architecture
S2 builds on a decoder-only transformer combined with an RVQ-based audio codec (10 codebooks, ~21 Hz frame rate). Flattening all codebooks along time would cause a 10× sequence-length explosion. S2 addresses this with a Dual-Autoregressive (Dual-AR) architecture:
- Slow AR operates along the time axis and predicts the primary semantic codebook.
- Fast AR generates the remaining 9 residual codebooks at each time step, reconstructing fine-grained acoustic detail.
This asymmetric design — 4B parameters along the time axis, 400M parameters along the depth axis — keeps inference efficient while preserving audio fidelity.
Reinforcement Learning Alignment for Speech
For post-training, S2 uses Group Relative Policy Optimization (GRPO), chosen to avoid the memory overhead of PPO-style value models in long audio contexts. The reward signal combines multiple dimensions, including:
- Semantic accuracy and instruction adherence
- Acoustic preference scoring
- Timbre similarity
Benchmark Results
S2 achieves leading results across multiple public benchmarks:
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chinese) | 0.54% (best overall) |
| Seed-TTS Eval — WER (English) | 0.99% (best overall) |
| Audio Turing Test (with instruction) | 0.515 posterior mean |
| EmergentTTS-Eval — Win Rate | 81.88% (highest overall) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — Quality | 4.51 / 5.0 |
| Multilingual (MiniMax Testset) — Best WER | 11 of 24 languages |
| Multilingual (MiniMax Testset) — Best SIM | 17 of 24 languages |
On Seed-TTS Eval, S2 achieves the lowest WER among all evaluated models including closed-source systems: Qwen3-TTS (0.77/1.24), MiniMax Speech-02 (0.99/1.90), Seed-TTS (1.12/2.25). On the Audio Turing Test, 0.515 surpasses Seed-TTS (0.417) by 24% and MiniMax-Speech (0.387) by 33%. On EmergentTTS-Eval, S2 achieves particularly strong results in paralinguistics (91.61% win rate), questions (84.41%), and syntactic complexity (83.39%).
Production Streaming via SGLang
Because S2's Dual-AR architecture is structurally isomorphic to standard autoregressive LLMs, it can directly inherit all LLM-native serving optimizations from SGLang with minimal modification — including continuous batching, paged KV cache, CUDA graph replay, and RadixAttention-based prefix caching.
For voice cloning, S2 places reference audio tokens in the system prompt. SGLang's RadixAttention automatically caches these KV states, achieving an average prefix-cache hit rate of 86.4% (over 90% at peak) when the same voice is reused across requests — making reference-audio prefill overhead nearly negligible.
On a single NVIDIA H200 GPU:
- Real-Time Factor (RTF): 0.195
- Time-to-first-audio: approximately 100 ms
- Throughput: 3,000+ acoustic tokens/s while maintaining RTF below 0.5
Why This Release Matters
S2 is released not as a model checkpoint alone, but as a complete system: model weights, fine-tuning code, and a production-ready inference stack.
Two design choices stand out. First, the unified data-and-reward pipeline eliminates a structural problem — distribution mismatch between pre-training and RL — that other TTS systems have not addressed at the architectural level. Second, the structural isomorphism between the Dual-AR architecture and standard LLMs means S2 can leverage the full ecosystem of LLM serving optimizations, rather than requiring custom inference infrastructure.
S2 is available via the project's GitHub repository, SGLang-Omni, HuggingFace, and interactive demo at fish.audio.



